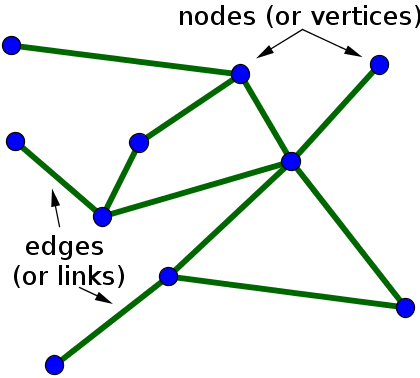
This is what Computer Scientists mean by a graph.
DJ Greaves - Corpus Christi College and Computer Laboratory.
This edition was prepared for the Bridging Course organised by Caius, King's and Christ's Colleges, August 2021.
I will host two sessions, broadly titled 'Hardware' and 'Software'.
The content should be very informative regardless of whether you have any computing experience, since they take a philosophical approach while still being packed with information that is very useful to anyone wanting to contribute to the next generation of hardware and software, which might use light or quantum effects instead of electricity.
The first session, Hardware, is largely pre-recorded, but we can chat at the end or after each video sequence. The second session, Software, will be far more interactive.
A very short introduction video, so you can see my face: Intro MP4.
Session 1 explains the history and fundamentals of digital computing, getting to the very basics of digital systems, what is meant by 'programming' and what an electronic computer is.
This session consists of three videos with a total running time of about 1.5 hours if you watch all of it at standard speed. However, you can skip the middle video if you are not very interested in hardware. But you'll ultimately need to know everything mentioned by the end of your first year on the Computer Science Tripos.
You may find that watching the videos at 1.5 times normal speed is a good idea, but pausing and replaying at points of interest.
The first video has the following major sections:
Watch here: Video 1 MP4.
The second video gives you some basic instruction in electrical circuits and then looks at how the telegraph influenced the design of electonic computers. It looks at how to store individual bits and introduces basic logic functions using relays and logic gates.
Watch here: Video 2 MP4.
The third video talks about computer arithmetic and describes how to build some important sub-circuits, such as adders and counters. The content here will all be covered in the CST Part Ia Digital Electronics course.
Watch here: Video 3 MP4.
Errata: Where I say the central gradient of the composed transfer function of two invertors is 'twice as much', I meant 'squared' as I had said just before. Caption ouput -> output, compnent -> component. Sentence at 10:46 about stateful truthtable is unfinished and digresses into clock speed.
Because computers have not really changed design from John von Neumann's seminal work, or even since the time of Babbage, knowledge of the history of computers is knowledge of today's computers!
The Hardware videos are based on content from here How Computers Work - DJ Greaves.
This session looks at the fundamental theory of programming, in terms of what is an algorithm, when two algorithms are the same as each other, using examples of the three primary forms of programming, which are functional, logical and imperative/procedural.
a) Why is the sum of the natural numbers up to N called a triangle number?
Triangle number computation (from Frank King): A Mathematician, an Engineer and a Computer Scientist each tackle the problem of summing the natural numbers up to N. The mathematician likes to use a formula. The Engineer writes a counting program that adds successive integers to an accumulating variable. The Computer Scientist says "I know the answer for N=1 is 1" and "If I know the answer for N-1 then I just need to add on N to that value." Write the programs in each style in your favourite programming language.
Mathematician (formula): # let sum_f n = n*(n-1)/2;; val sum_f : int -> int =# sum_f 10;; - : int = 45 Engineer (imperative): # let sum = ref 0;; val sum : int ref = {contents = 0} # let rec sum_imp n = sum := 0; if n=0 then !sum else (sum := !sum + n; sum_imp(n-1));; val sum_imp : int -> int = # sum_imp 10;; - : int = 55 Computer Scientist (recursion/induction): # let rec sum_m n = if n=1 then 1 else n + sum_m(n-1);; val sum_m : int -> int = # sum_m 10;; - : int = 55
Three paradigms: Imperative (procedural), Declarative (functional), and Logic Programming. Can we program without ever changing the values in any register?
The Engineer above used imperative programming. The Mathematician used maths. The Computerist deployed 'divide and conquer' and recursion using declarative/functional programming.
b) What is a declaration?
c) The code for each case is sketched above. Which is easiest to reason about. Can you give me a logical formula (a loop invariant) that holds for each iteration of the imperative version. (Hint: it will say something like, each time we restart the loop, the value held in sum is equal to the ....). Is this easier to formulate for the recursive variant?
d) What is the difference between functional and declarative programming? Can we 'run' a purely declarative program since 'run' is a command which is imperative?
The Euclid Algorithm code in Video 1 used a SWAP instruction.
PC 1 PRINT "R1=",R1,", R2=",R2 2 IF R1=0 THEN 7 3 IF R1 < R2 THEN 5 4 SWAP R1,R2 5 R2 := R2 - R1 6 GOTO 1 7 HALT
If SWAP were not a primitive operation in our language, would the following subroutine provide a suitable implementation:
SWAP(R1, R2)
{
R3 := R2;
R2 := R1;
R1 := R3;
}
Here is a possible alternative swap routine that uses bitwise exclusive-OR (e.g. 5 ^ 3 = 6).
SWAP(R1, R2)
{
R2 := R1 ^ R2;
R1 := R1 ^ R2;
R2 := R1 ^ R2;
}
What is a graph? A plot of a function against and independent variable? Not in computer science.
This is what Computer Scientists mean by a graph.
Network Diameter: Consider 100 telegraph stations around the coast of a large, roughly-circular country, like Australia. Nobody lives in the middle. (See video 2 above for telegraph station principles). If a single telegraph link can cross the diameter or the country, how should the system be set up so that a telegram can be sent from any station to any other? For Australia, there would need to be tens of repeaters to cross the diameter. How does this change things? Start by considering some very simple situations and analysing the amount of wire and equipment needed and the number of relay steps encountered by a typical message.
Various algorithms can compute the same result: e.g. finding the shortest distance between A and B in a directed graph.
Discussion. Which is more efficient on a parallel computer? Are they the same algorithm? What is a semantic-preserving rewrite?
Returning to the Engineer's code for triangle numbers, and comparing it with the Computer Scientist's code, are these the same algorithms?
This was the Computer Scientists code:
let rec sum_m n = if n=1 then 1 else n + sum_m(n-1);;
Suppose we rewrite it such that it takes an auxiliary argument, c, like this:
let rec sum_mc c n = if n=1 then 1+c else sum_mc (n+c) (n-1);;
This rewrite of the code can be automated (2nd-year Compiler Construction course continuation passing materials) and, moreover, a typical ML compiler will convert this program into the Engineer's form for internal execution (no stack will be needed). Hence, if all of the transformations required to convert one to the other are mechanised, can we consider the two programs to implement the same algorithm?
Of course the Mathematician used maths to obtain his formula. Whether he used an automated program to do his maths is a question for religion and philosophy --- was he predestined to do that bit of maths?
record person_record; name : char []; year_of_birth: int; month_of_birth: int; day_of_birth: int; mothers_age_at_birth: int; end
Object:
object person_object;
name : char [];
year_of_birth: int;
month_of_birth: int;
day_of_birth: int;
mothers_age_at_birth: int;
bool is_ripe() { return current_year - year_of_birth > mothers_age_at_birth; }
end
a) In mathematics, what does 'finding the root(s) of an equation' mean? Give a formal definition if you can (i.e. use a clear sentence).
With logic programming we do not write the program ourselves. We write a declarative formula that we want the system to satisfy.
The most famous logic programming language is PROLOG. But also SQL, structured query language, used for realtional databases, is a good example.
Do you have a database program installed on your machine? On my machine the command 'sqlite3' is installed so I will use that.
create table parts(part_no, part_name, supplier, cost INTEGER);
insert into parts values('101', "front-fork", "ACME Ltd", 20);
insert into parts values('102', "crank-arm", "ACME Ltd", 10);
insert into parts values('202', "chain", "Manchester Bike Parts Ltd", 3);
insert into parts values('103', "pedal", "ACME Ltd", 5);
insert into parts values('103', "wheel", "ACME Ltd", 15);
insert into parts values('103', "bell", "Birmingham Steel Solutions", 2);
insert into parts values('1103', "large frame", "Birmingham Steel Solutions", 41);
insert into parts values('1104', "small frame", "Birmingham Steel Solutions", 31);
insert into parts values('403', "saddle", "Bognor Leather Goods Ltd", 4);
insert into parts values('203', "saddlebag", "Bognor Leather Goods Ltd", 5);
# Here is the data for just one product, but typically there will be a number of products based on the same catalogue of parts.
create table product(product_name, part_instance_name, bike_part_name);
insert into product values("Slicer", "front wheel", "wheel");
insert into product values("Slicer", "back wheel", "wheel");
insert into product values("Slicer", "frame", "large frame");
insert into product values("Slicer", "left pedal", "pedal");
insert into product values("Slicer", "right pedal", "pedal");
insert into product values("Slicer", "left crank arm", "crank-arm");
insert into product values("Slicer", "right crank arm", "crank-arm");
insert into product values("Slicer", "fork", "front-fork");
We'll do a demo in this session. If you are unfamiliar with databases, everything will be properly explained in the first term of the Tripos.
b) What is the SQL query to get the cost of goods for a Slicer bike?
c) What is a relational database?
d) What is a key and what is the key for the parts database?
Try running each of these queries in turn and see if you can understand the output.
1 select * from product, parts; 2 select * from product, parts where bike_part_name = part_name; 3 select cost from product, parts where bike_part_name = part_name; 4 select SUM(cost) from product, parts where bike_part_name = part_name; 5 select SUM(cost) from product, parts where bike_part_name = part_name && cost < 33;
Some harder or more philosophical questions:
e) Is the data normalised? This means could the tables be reorganised so that the data stored in every table is 'functionally dependent' on the key of each table.
f) Suppose we want to store all of the components involved with pedals just once so they can be conveniently used over multiple products? Can we reorganised the tables to help with that?
g) How could we be sure that every product has a chain?
h)Is the relational style ideal for lists of components?
Prolog is another logic programming language. Here is a fragment where we define relations between atoms and then a rule for inferring further relationships.
father(Charles, Harry); father(Charles, William); father(Philip, Charles); grandfather(X, Z) :- father(X, Y), father(Y, Z);
As well as simple atoms, Prolog allows you to define relationships between 'algebraic structures' such as lists and trees, so for instance, you can define a list of N elements to be the concatenation of any two appropriate sub-lists that when appended become the initial list:
append( [], X, X).
append( [X | Y], Z, [X | W]) :- append( Y, Z, W).
This defines a relationship between the three arguments, let's say A, B and C.
The first line says, " C is the result of appending A and B if A and C are non-empty lists, they both have the same head (i.e. first element),
and the tail of C is the result of appending the tail of A with the same 2nd argument, B".
(From https://stackoverflow.com/questions/11539203/how-do-i-append-lists-in-prolog/11551001)
For reasoning about stable chemical formulae, you can use facts like 'divalent(Oxygen)' and 'monovalent(Hydrogen)' along with suitable valency rules to allow the molecule H2O but not HO.
Many logic programs can be converted to a Boolean Satisfiability problem (SAT). SAT solver tools are then able to find solutions of hundreds of bits, despite that a brute-force search would require more than a universe lifetime on the fastest possible computer.
The satisfiability problem is: given a Boolean expression over some number of variables, find a setting for those variables that makes the expression true.
For simple problems, such as ABC + BE~A, two obvious solutions are "A=1, B=1, C=1" and "A=0, B=1, E=1", but for tens or hundreds of variables, the problem becomes much harder. (Indeed it is one of the problems called exponentially hard in Complexity Theory). But given a suggested solution, that can be rapidly checked, so this is an example of a problem where the search can usefully be run on an unreliable computer.
There may be a huge role for unreliable computers in the future. A computer run on a very low supply voltage will be unreliable yet not use much electricity. Hence it might be beneficial. Likewise, a computer made of components a few atoms across can suffer from a lot of fabrication mistakes and might fall apart (electromigration) fairly rapidly. But owing to its small size, it too will use very little electricity and hence still play a useful part.
Logic programming example from cryptography: We have the encrypted message O0 that encodes x and a sufficient number of known input/output (plain/cyphertext) pairs under a given key. The satisfiability problem is then find x such that I1 ~ O1 && I2 ~ O2 && ... && x ~ O0.
Methods of making stable chemicals can also be discovered using logic programming. Knowing what a new chemical might be useful for is another matter. But drugs companies can use logic programming to discover a cheap process for synthesising new chemicals and then medical experiments can be run to see if the resulting compounds are useful for anything. For instance, the logic program might generate a list of all stable chemicals that can be cheaply generated from the available source compounds and with the available processing equipment. Or it might find a (new) way (recipe) for synthesising a given target compound of interest, such as methotrexate. The possibilities are endless.
Here's a paper.
'When are two algorithms the same?' by ANDREAS BLASS, NACHUM DERSHOWITZ, AND YURI GUREVICH. Abstract.People usually regard algorithms as more abstract than the programs that implement them. The natural way to for- malize this idea is that algorithms are equivalence classes of pro- grams with respect to a suitable equivalence relation. We argue that no such equivalence relation exists. PDF.
Does it agree with my notion that two algorithms are the same if there exists a holy set of automated rewrites that can make the transform there are back? Afterall, how can one rewrite procedure produce two outputs? This would perhaps imply that all versions of an algorithm exist in a ring and the procedure always set shunts us to the next one? Perhaps a reduction to normal form approach could work better: any version of an algorithm is equivalent if the normal form transformations are textually equivalent? Can we prove that a program cannot have a normal form?
Adverts:
August 2021: Read my book Modern SoC Design on Arm Free PDF Download
August 2021: Stream my single Let Me Love You Anneli UK: YouTube Anneli UK:Apple Music.
(C) All materials (except some photos) DJ Greaves 2021. Google keyword Philo-HCW-DJG.