It is widely accepted that many problems in scientific computing can be vastly accelerated using either dedicated hardware or GPU execution resources. Custom silicon implementation using ASIC gives at least an order of magnitude energy saving as an additional benefit. FPGA is less efficient than ASIC but requires orders of magnitude less investment in design time and non-recurring cost. However, an FPGA design may still take many hours to compile which is inconvenient when the performance achieved after this investment was less than expected. Using high-level synthesis (HLS), tools such as Kiwi, LegUp or Catapult-C it is relatively quick and easy to convert an algorithm from software to hardware form, but these tools can sometimes produce poor results and discovering exactly why has often been very difficult. Owing to the lengthy compile times, it is tiresome to test small design changes, but these are typically the only basis available to guide iterative improvement of the implementation.
Issues that commonly arise when addressing Scientific Computing with FPGA targets are:
The following single-threaded code has three variant algorithms and one major scaling parameter.
// primesya.cs - Sieve of Eratosthenes demo.
// Kiwi Scientific Acceleration
// $Id: primesya.cs,v 1.7 2011/06/08 17:45:10 djg11 Exp $
// (C) 2010 - DJ Greaves - University of Cambride Computer Laboratory
using System;
using KiwiSystem;
/*
Example runtimes on mono (no Kiwi) for 100K (intel i5-3337 @1.8GHz)
A lot of prints here, so a bit slow, but shows the effect of evariation.
evariant=0 real 0m10.501s user 0m4.798s sys 0m5.763s
evariant=1 real 0m4.870s user 0m2.288s sys 0m2.612s
evariant=2 real 0m3.502s user 0m1.571s sys 0m1.952s
*/
// There are three (at least) variations on this program that vary in efficiency but give the same result.
// They vary in the their control flow graphs.
// Performance predictor questions:
// 1. Can we extrapolate the performance within one variation to larger runs ?
// 2. Can we estimate the performance of the optimised code from the non-optimised code?
//
// The extrapolation is complicated by the DRAM banks, because the smaller runs operate within one row of each bank so there is now row writeback and precharge overhead. For the latter crossoff stages, this becomes a significant overhead owing to the wide strathe between accesses.
//
// Adding a DRAM cache makes little difference owing to excessive churn, but could we automatically predict that ?
//
class primesya
{
// The following major parameter is edited by a sed script invoked by the Makefile before each run.
// It needs to be a compile-time constant since Kiwic chooses what type of memory organisation to use based on its value.
static int limit = 1000 * 100;
static bool [] PA = new bool[limit]; // Placed in off-chip DRAM owing to its size.
// This input port, vol, was added to make some input data volatile.
[Kiwi.InputWordPort(31, 0)][Kiwi.OutputName("volume")] static uint vol;
[Kiwi.OutputWordPort(31, 0)][Kiwi.OutputName("count")] static uint count = 0;
static int count1 = 0;
[Kiwi.OutputWordPort(31, 0)][Kiwi.OutputName("elimit")] static int elimit = 0; // The main scaling parameter (abscissa).
// The variant is also edited by a sed script that runs an individual experiment.
[Kiwi.OutputWordPort(31, 0)][Kiwi.OutputName("evariant")] static int evariant = 2; // The alogorithmic variant - must hold when finish is asserted.
[Kiwi.OutputWordPort(31, 0)][Kiwi.OutputName("edesign")] static int edesign = 4032; // A uid for this program
[Kiwi.OutputBitPort("finished")] static bool finished = false;
[Kiwi.HardwareEntryPoint()]
public static void Main()
{
bool kpp = true;
elimit = limit;
Kiwi.KppMark("START", "INITIALISE"); // Waypoint
Console.WriteLine("Primes Up To " + limit);
Kiwi.Pause();
PA[0] = vol > 0; // Process some runtime input data on this thread - prevents Kiwic running the whole program at compile time.
Kiwi.Pause();
// Clear array
count1 = 2; count = 0; // RESET VALUE FAILED AT ONE POINT: HENCE NEED THIS LINE
for (int woz = 0; woz < limit; woz++)
{
PA[woz] = true;
Console.WriteLine("Setting initial array flag to hold : addr={0} readback={1}", woz, PA[woz]); // Read back and print.
}
Kiwi.KppMark("wp2", "CROSSOFF"); // Waypoint
int i, j;
for (i=2;i<limit; i++) // Can our predictor cope with the standard optimisations?
{
// Cross off the multiples - optimise by skipping where the base is already crossed off.
if (evariant > 0)
{
bool pp = PA[i];
Console.WriteLine(" tnow={2}: check back {0} = {1} ", i, pp, Kiwi.tnow);
if (!pp) continue;
count1 += 1;
}
// Can further optimise by commencing the cross-off of the factor squared.
j= (evariant > 1) ? i*i : i;
if (j >= limit)
{
Console.WriteLine("Skip out on square");
break;
}
for (; j<limit; j+=i)
{
Console.WriteLine("Cross off {0} {1} (count1={2})", i, j, count1);
PA[j] = false;
}
}
Kiwi.KppMark("wp3", "COUNTING"); // Waypoint
Console.WriteLine("Now counting");
// Count how many there were and store them consecutively in the output array.
for (int w = 0; w < limit; w++)
{
if (PA[w])
{
count += 1;
}
Console.WriteLine("Tally counting {0} {1} at {2}", w, count, Kiwi.tnow);
}
Console.WriteLine("There are {0} primes below the natural number {1}.", count, limit);
Console.WriteLine("(count1 is {0}).", count1);
Kiwi.Pause();
finished = true;
Kiwi.Pause();
Kiwi.KppMark("FINISH"); // Waypoint
Kiwi.Pause();
}
}
// eof
We note the above design invokes KppMark to designate 'waypoints' that are articulation points in the control flow graph. Variations of the design can be compared and where the control-flow graph between waypoints is unchanged from when performance data was captured the performance predictor has confidence in the relative visit ratios between control-flow states.
The above design generates RTL output under the Kiwi compiler. Example Output 425 lines of Verilog RTL.
module SIEVE_DUT(
output reg [639:0] KppWaypoint0,
output reg [639:0] KpSWaypoint1,
input [31:0] volume,
output reg [31:0] count,
output reg signed [31:0] elimit,
output reg signed [31:0] evariant,
output reg signed [31:0] edesign,
output reg finished,
output reg hf1_dram0bank_opreq,
input hf1_dram0bank_oprdy,
input hf1_dram0bank_ack,
output reg hf1_dram0bank_rwbar,
output reg [255:0] hf1_dram0bank_wdata,
output reg [21:0] hf1_dram0bank_addr,
input [255:0] hf1_dram0bank_rdata,
output reg [31:0] hf1_dram0bank_lanes,
input clk,
input reset);
It connects to a single DRAM subsystem with the hf1_xnets that is cached and the synthesis expects each DRAM access cycle to hit in the cache and be served in a single clock cycle.
The Kiwi compiler writes an XML file describing the design that will be imported by the performance predictor (XML 198 lines).
Simulation runs write XML files providing data points
Console output from the simulation (snipped at ...)
Primes Up To 100
6000: pc= 17: new waypoint monitored START
Setting initial array flag to hold : addr= 99 readback=1
...
1533000: pc= 15: new waypoint monitored wp2
tnow= 0: check back 2 = 1
...
3267000: pc= 8: new waypoint monitored wp3
...
Tally counting 97 27 at 0
Tally counting 98 27 at 0
Tally counting 99 27 at 0
There are 27 primes below the natural number 100.
Optimisation variant=2 (count1 is 7).
finished at 5068000 after 5064 clocks
pc visit count report kpp_hwm= 18
wp= 0, pc visit counts, 0, 5
wp= 1, pc visit counts, 13, 1411
wp= 1, pc visit counts, 14, 99
wp= 1, pc visit counts, 16, 1
wp= 1, pc visit counts, 17, 15
wp= 1, pc visit counts, 18, 1
wp= 2, pc visit counts, 1, 1376
wp= 2, pc visit counts, 2, 98
wp= 2, pc visit counts, 4, 4
wp= 2, pc visit counts, 10, 75
wp= 2, pc visit counts, 11, 170
wp= 2, pc visit counts, 12, 10
wp= 2, pc visit counts, 15, 1
wp= 3, pc visit counts, 7, 1
wp= 3, pc visit counts, 8, 100
wp= 3, pc visit counts, 9, 1700
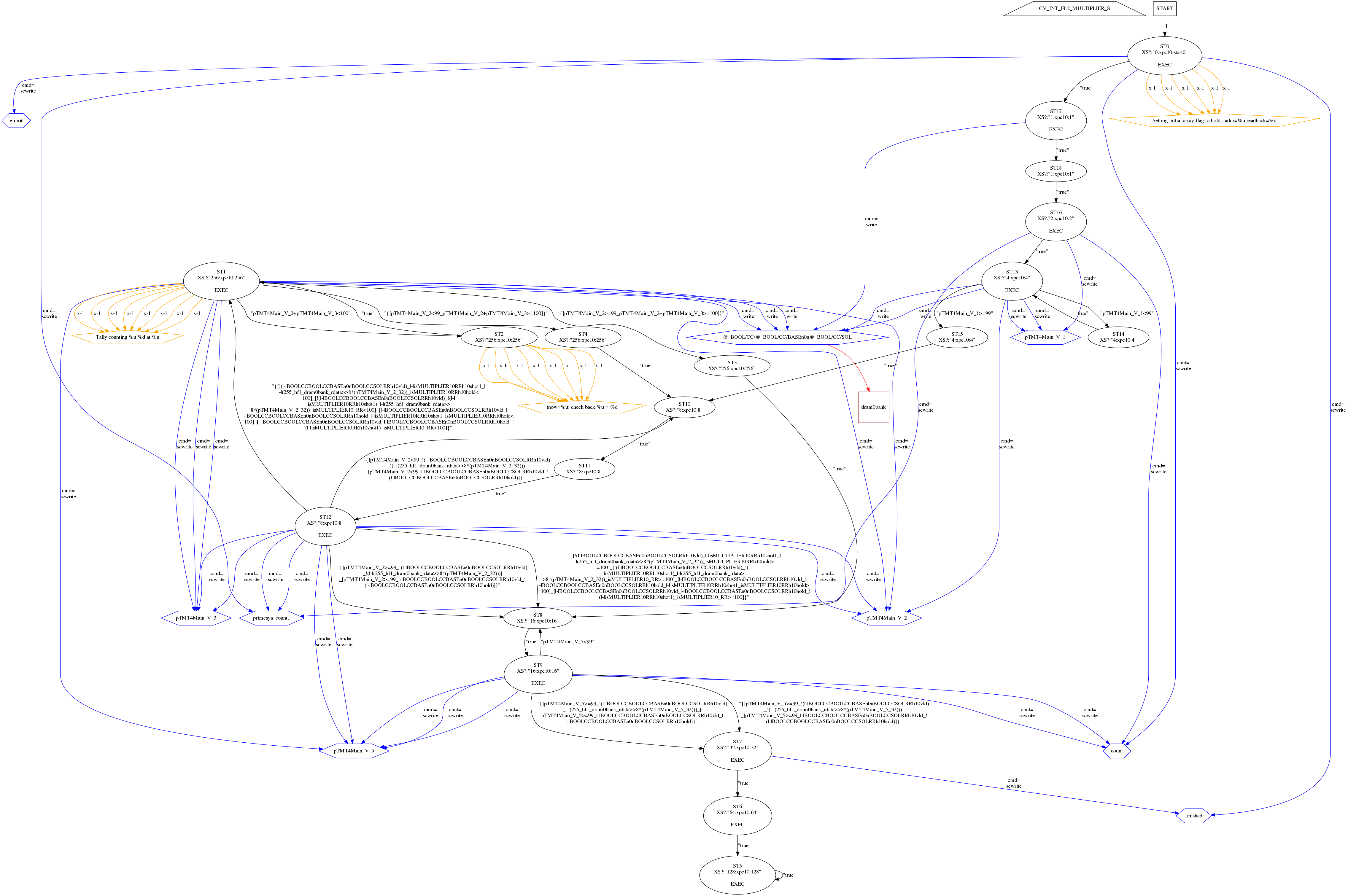
The three phases of the program, between the two way points, are clear in the following VCD dump of a very small run that finds the primes below 100. (In this run, the system was forced, via command line flags, to use DRAM for the bool array, despite the very small size. And no cache was interposed, meaning that the design is stalled for 11 or so clock cycles for each array operation, even though it was schedulled to expect only one.) In real systems, the DRAM runs six times faster than the FPGA logic, reducing 11 to 2, and a cache is present, that would have only compulsorary misses for such a small array. Note, 'woz' is V_0, and i and j are V_1 and V_2 etc..
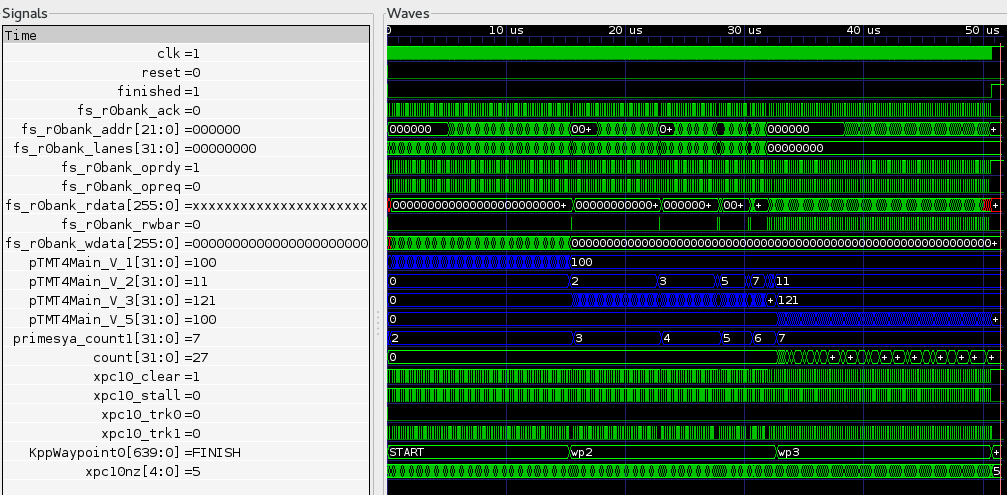
Example simulation run profile profile.xml.
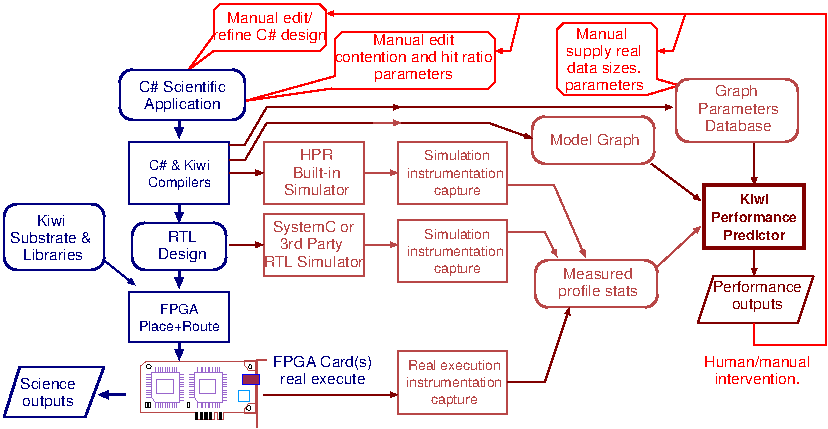
The general flow of the predictor is illustrated in this figure.
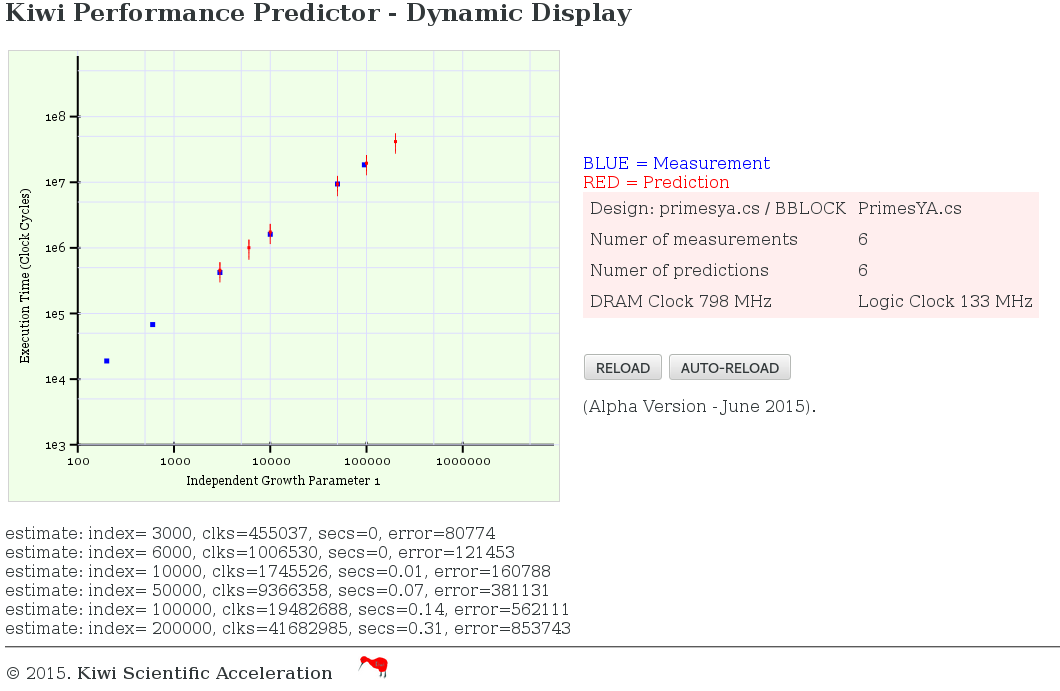
... under construction
(C) 2015 DJ Greaves. Back link: Kiwi Home.